Updated: Hint - I posted this one day early for effect. Read some of the comments in that light - verrrry funny :)
The future is here.
We're not quite ready to release it widely yet, but I've VERY excited about a breakthrough in our use and understanding of browser embedded applications. Its not AJAX, but it is AJAX-y.
While many companies and start-ups are struggling with basic online applications like weak Word Processors and pokey productivity tools and lame web page editors that Desktop applications already dealt with much better in the last century - WE are going to leap frog them with the ultimate Mash-up-able Web 2.0 AJAX-y JSON-based content runtime.
This new technology will finally and forever end the debates about Firefox vs Internet Explorer vs Opera vs Safari, in the same way the original browser conclusively eliminated the debate about which Operating System was better - it just didn't matter anymore.
As my grandmother's Podiatrist used to always say:
You can't nail the problems of the future with hammers from the past.
I'm pleased to announce the alpha release of the first portable Browser Based Browser: B-Three!
- B3! runs RIGHT in your browser - no install required.
- B3! is 100% compatible with your existing browser, and never requires any updating - features stream in just as you need them/use them.
- B3! has NO requirements and requires nothing to be installed (except a Browser)
- Its only an alpha, so be gentle - MANY more exciting features will be coming soon (automagically).
The future is now (er... plus the three minutes it took you to read this post).
Go check it out.
Once you B3!, you won't remember before.
(beFOUR- get it?)
March 31, 2006
March 30, 2006
Web 3.0: Dot-com-umentary Movie Script redux
Enough pontificating. Time for something fun :)
All of this Web 2.0, AJAX, etc. hype sent me on a nostalgic stroll down memory lane. At one point (I want to say 2001? 2002?) I had this idea for a movie - a pseudo-documentary about the dot-com world.
[yeah, yeah - I worked in Manhattan at the time *and* was working in Marketing - gimme a break :)]
In any case, I only ever wrote the first scene, though I had an outline for the whole movie.
The basic plot was about these two guys who have a "business" plan, raise money, start a company, hire employees, have a launch party, realize the folly of their path, switch business models completely, try to sell the company, and go out of business ALL IN ONE DAY.
And their business model was pure Internet visionary GENIUS!!! The idea was to... - well, you'll have to read it for yourself.
I called it: Dot-com-umentary.
Enjoy!
(That means you can read the opening scene here as written a few years ago - unedited except for some formatting)
Maybe I'll finish it - its still pretty relevant :P
And thanks to a friend for digging it up so promptly - I couldn't find it! :)
Creepy similarities, hunh? The silliness is BACK, baby!
All of this Web 2.0, AJAX, etc. hype sent me on a nostalgic stroll down memory lane. At one point (I want to say 2001? 2002?) I had this idea for a movie - a pseudo-documentary about the dot-com world.
[yeah, yeah - I worked in Manhattan at the time *and* was working in Marketing - gimme a break :)]
In any case, I only ever wrote the first scene, though I had an outline for the whole movie.
The basic plot was about these two guys who have a "business" plan, raise money, start a company, hire employees, have a launch party, realize the folly of their path, switch business models completely, try to sell the company, and go out of business ALL IN ONE DAY.
And their business model was pure Internet visionary GENIUS!!! The idea was to... - well, you'll have to read it for yourself.
I called it: Dot-com-umentary.
Enjoy!
(That means you can read the opening scene here as written a few years ago - unedited except for some formatting)
Maybe I'll finish it - its still pretty relevant :P
And thanks to a friend for digging it up so promptly - I couldn't find it! :)
Creepy similarities, hunh? The silliness is BACK, baby!
March 29, 2006
Provably Better, pt 2: Web 2.0, Syndication
and the Interpersonal Internet
[Continued from Part 1]
The truly successful, disruptive initiatives (and companies: Google, Amazon, E-Bay, ec.) on the Internet have been successful not only in syndicating their content, and in syndicating their technologies - they've successfully syndicated their very business models.
You make money making money for them.
While there's been all this discussion of B2B and B2C and clicks-and-mortar businesses, the real Internet has been subtly altering the business landscape by cracking the C2B (consumer-to-business) code: enhancing consumer behaviours and values through a positive reinforcement of traffic and, ultimately, dollars.
E-Bay (including PayPal) is only the most obvious and literal form of this. As people have known for some time, its not just about the direct benefit, but also about the ancillary traffic and goodwill they don't have to work to generate.
And because of this positive spiral they've spun up, these are not just the successful endeavors of today: they are poised to capture ongoing opportunities in the marketplace.
This is the new network effort - and I'd argue that its provably better.
But my key point is this - its NOT, nor will it EVER be, an insurmountable lead (in principle :P); the rapid rise of Skype, MySpace, and even Google itself prove that the real value of this Interpersonal Internet is still PEOPLE.
Humans are the node leaves of the network, and we're a fickle bunch :) As trust metric attack pathology demonstrates, this network can be attack resistant, but only for as long as you do good.
Perhaps "Do No Evil" is a cannier mission than we think.
Perhaps it recognizes a substantial truth, that this Interpersonal Internet (I2?) is enabled through people as the endpoints: the "last mile" is always about us - if that's not too very old media.
The truly successful, disruptive initiatives (and companies: Google, Amazon, E-Bay, ec.) on the Internet have been successful not only in syndicating their content, and in syndicating their technologies - they've successfully syndicated their very business models.
You make money making money for them.
While there's been all this discussion of B2B and B2C and clicks-and-mortar businesses, the real Internet has been subtly altering the business landscape by cracking the C2B (consumer-to-business) code: enhancing consumer behaviours and values through a positive reinforcement of traffic and, ultimately, dollars.
E-Bay (including PayPal) is only the most obvious and literal form of this. As people have known for some time, its not just about the direct benefit, but also about the ancillary traffic and goodwill they don't have to work to generate.
And because of this positive spiral they've spun up, these are not just the successful endeavors of today: they are poised to capture ongoing opportunities in the marketplace.
This is the new network effort - and I'd argue that its provably better.
But my key point is this - its NOT, nor will it EVER be, an insurmountable lead (in principle :P); the rapid rise of Skype, MySpace, and even Google itself prove that the real value of this Interpersonal Internet is still PEOPLE.
Humans are the node leaves of the network, and we're a fickle bunch :) As trust metric attack pathology demonstrates, this network can be attack resistant, but only for as long as you do good.
Perhaps "Do No Evil" is a cannier mission than we think.
Perhaps it recognizes a substantial truth, that this Interpersonal Internet (I2?) is enabled through people as the endpoints: the "last mile" is always about us - if that's not too very old media.
March 28, 2006
Provably Better, pt 1: Web 2.0, Syndication
and the Interpersonal Internet
People tend to overlook one of the real divides between the old order and the new - New Media, the New New Thing, etc. - what is the cycle the drives commerce and monetization?
Web 2.0 tries to capture some of that delta with its notion of a "Participatory Web" or "Web as Platform". And from an end user and developer perspective, respectively, I think that indeed gets at some of the core elements.
However, from a business and cultural perspective, I think its at once simpler than that and deeper than that. One of the foundational promises of the Internet was in enabling many-to-many communication: arbitrary people connection graphs, if you will - and in large measure, its done that. Websites, homepages, e-mail, IM, message boards, blogs, etc. CONNECT people - IP address and physical location are among the least interesting ways that we address anymore (voice/cel is still key and I think tandem addresses will enable yet another layer of services - more on that another time).
Further, I'd argue that at the core of that networking is Syndication. And yes, I mean syndication in every sense of the word - even social networking is about trust metric driven, loosely coupled, syndication networks, where tagging, rating and social connections drive trust (and therefore traffic). As always though, this works best when greased with the fiscal incentives syndication can drive at scale.
Web 2.0 tries to capture some of that delta with its notion of a "Participatory Web" or "Web as Platform". And from an end user and developer perspective, respectively, I think that indeed gets at some of the core elements.
However, from a business and cultural perspective, I think its at once simpler than that and deeper than that. One of the foundational promises of the Internet was in enabling many-to-many communication: arbitrary people connection graphs, if you will - and in large measure, its done that. Websites, homepages, e-mail, IM, message boards, blogs, etc. CONNECT people - IP address and physical location are among the least interesting ways that we address anymore (voice/cel is still key and I think tandem addresses will enable yet another layer of services - more on that another time).
Further, I'd argue that at the core of that networking is Syndication. And yes, I mean syndication in every sense of the word - even social networking is about trust metric driven, loosely coupled, syndication networks, where tagging, rating and social connections drive trust (and therefore traffic). As always though, this works best when greased with the fiscal incentives syndication can drive at scale.
Let me explain (in part 2 :)).
March 27, 2006
Developers and Permissive Parsing
Don't do it. Require strictness whenever you implement a parser of ANY kind.
People always ask: why should compatibility be at odds with standards compliance? This is why.
Back in the day, when Netscape was king of the hill and the web was dawning in the consumer eye (by that I mean $ ka-ching $), permissive parsing was all the rage. Mostly, to make it easy on content creators, the browser was just supposed to “work” if it could - and this extended to mark-up as well as script.
Turns out this was remarkably wrong-headed thinking, though we (the industry royal “we” here) all fell victim to its lure - and suffer the consequences as a result.
Unfortunately, there are now very real places where compatibility and standards compliance are directly at odds - permissive parsing means its hard to tell what the "right" thing to do is, especially as technology and standards evolve. If strictness and unit testing were the rule of the day, that wouldn't be the case.
This is a classic example (to me) of experience vs. intellect. It seems better to make it easier for your users, but it actually just makes things awful for everybody, over time, every time.
Be sure you explicitly define what doesn't work as you define what does.
Or, as I'm fond of saying:
Never put off tomorrow what you can put off today.
People always ask: why should compatibility be at odds with standards compliance? This is why.
Back in the day, when Netscape was king of the hill and the web was dawning in the consumer eye (by that I mean $ ka-ching $), permissive parsing was all the rage. Mostly, to make it easy on content creators, the browser was just supposed to “work” if it could - and this extended to mark-up as well as script.
Turns out this was remarkably wrong-headed thinking, though we (the industry royal “we” here) all fell victim to its lure - and suffer the consequences as a result.
Unfortunately, there are now very real places where compatibility and standards compliance are directly at odds - permissive parsing means its hard to tell what the "right" thing to do is, especially as technology and standards evolve. If strictness and unit testing were the rule of the day, that wouldn't be the case.
This is a classic example (to me) of experience vs. intellect. It seems better to make it easier for your users, but it actually just makes things awful for everybody, over time, every time.
Be sure you explicitly define what doesn't work as you define what does.
Or, as I'm fond of saying:
Never put off tomorrow what you can put off today.
March 25, 2006
AOL: Why we will win, pt 2 (why not)
I wrote in part 1 that AOL would win because:
3) We have scale (of audience, infrastructure, and marketing)
2) We still have a highly engaged relationship with known customers
1) We have a well known, wide reaching brand
Continuing my All-Hands speech from last year:
Greatness is forged in the fire of great opportunity, and that's what the above add up to me: great opportunity.
That's why we can win. However, its not all motherhood and apple pies. We have some challenges.
And why AOL won't win...
3) Identity
What is the mission of AOL? Who ARE we? In a world where AOL inarguably helped get people connected and, more or less, saw the Company's original mission fulfilled and then ursurped - what does AOL stand for? "Revenue transformation", "More customers", and "OIBIDA targets" are not exactly rousing missions... those are vaguely Dilbertesque business goals.
2) Relevance
Directly related to the previous point, but, when AOL does things, even good things, do people care anymore? Not nearly enough, I'd say - there's a trust in our future AOL has to rebuild: with users, the press, investors, and even ourselves. When people talk about Internet companies, AOL often don't even make the list.
1) Brand rejectors
On this point, most people think I mean AOL's brand perception in the market at large. Yeah, that's a problem, but as the old adage goes: there's no such thing as bad publicity. No, I'm talking about something far more insidious: there are too many people who hate AOL who work at AOL. It disappoints me to hear employees talk about "non-members" as our future (the term, not the concept, bothers me because of what it implies about our self esteem). If people are in our namespace, if they use our software, we should be inclusive in our view of them as "members" of our services. There is a deep condescension at work there. And it disappoints me to see the rejection of terms like "AOL Experience" - it ought to be something we work to be proud of, dammit, not something we want to leave behind. We have too many brand rejectors who work here, and you have to believe to succeed.
In my view, our BIGGEST problem is that because there is often this subtle self-loathing in our culture, we're too busy, as a company, copying where we should be leading. If we're not chasing a press relese, or the latest flash-in-the-pan "disruptive technology"(remember [EDITED FOR PUBLIC CONSUMPTION] or [EDITED FOR PUBLIC CONSUMPTION], anybody?), we're busy copying (read: being constrained by) our past.
We CAN compete, but we have to recognize that there is no magic; there are no silver bullets. It takes vision, commitment, and hard work.
Most importantly, AOL is best when we're defining the rules, not conforming to them.
And, like dignity, this self-definition comes from the inside out - as Eleanor Roosevelt said so well, "No one can make you feel inferior without your consent".
3) We have scale (of audience, infrastructure, and marketing)
2) We still have a highly engaged relationship with known customers
1) We have a well known, wide reaching brand
Continuing my All-Hands speech from last year:
Greatness is forged in the fire of great opportunity, and that's what the above add up to me: great opportunity.
That's why we can win. However, its not all motherhood and apple pies. We have some challenges.
And why AOL won't win...
3) Identity
What is the mission of AOL? Who ARE we? In a world where AOL inarguably helped get people connected and, more or less, saw the Company's original mission fulfilled and then ursurped - what does AOL stand for? "Revenue transformation", "More customers", and "OIBIDA targets" are not exactly rousing missions... those are vaguely Dilbertesque business goals.
2) Relevance
Directly related to the previous point, but, when AOL does things, even good things, do people care anymore? Not nearly enough, I'd say - there's a trust in our future AOL has to rebuild: with users, the press, investors, and even ourselves. When people talk about Internet companies, AOL often don't even make the list.
1) Brand rejectors
On this point, most people think I mean AOL's brand perception in the market at large. Yeah, that's a problem, but as the old adage goes: there's no such thing as bad publicity. No, I'm talking about something far more insidious: there are too many people who hate AOL who work at AOL. It disappoints me to hear employees talk about "non-members" as our future (the term, not the concept, bothers me because of what it implies about our self esteem). If people are in our namespace, if they use our software, we should be inclusive in our view of them as "members" of our services. There is a deep condescension at work there. And it disappoints me to see the rejection of terms like "AOL Experience" - it ought to be something we work to be proud of, dammit, not something we want to leave behind. We have too many brand rejectors who work here, and you have to believe to succeed.
In my view, our BIGGEST problem is that because there is often this subtle self-loathing in our culture, we're too busy, as a company, copying where we should be leading. If we're not chasing a press relese, or the latest flash-in-the-pan "disruptive technology"(remember [EDITED FOR PUBLIC CONSUMPTION] or [EDITED FOR PUBLIC CONSUMPTION], anybody?), we're busy copying (read: being constrained by) our past.
We CAN compete, but we have to recognize that there is no magic; there are no silver bullets. It takes vision, commitment, and hard work.
Most importantly, AOL is best when we're defining the rules, not conforming to them.
And, like dignity, this self-definition comes from the inside out - as Eleanor Roosevelt said so well, "No one can make you feel inferior without your consent".
March 23, 2006
AOL: Why we will win, pt 1
Carl Hutzler's recent post got me thinking. I agree strongly with the contents of his message, though I think it also requires burning the candle from multiple ends.
Below are my speech notes from one of my All Hands presentations in the second half of last year (2005) - its a little out of context today, but I still thought it worth sharing.
Why AOL will win...
3) We have scale.
We have scale of audience, infrastructure, and marketing. 110M out of 160M or so Internet users in the US touches an AOL, Inc website (not counting TWX in this). And, our infrastructure is built to scale: no else could have pulled off Live8, for example - even Akamai's edge Network isn't in our capacity league. And its not just technical scale - we're a marketing powerhouse. We cycle [EDITED FOR PUBLIC CONSUMPTION] out of [EDITED FOR PUBLIC CONSUMPTION] households in the US through our acquisition channels EVERY YEAR. And that scale is relevant.
2) We have engagement.
More than half the Internet population in the U.S. launches one of our core desktop products alone - other than Windows, Office, and Solitaire (seriously) I don't think anything or anyone comes close to our usage. Our ENGAGED user base dwarfes the total OS X and Linux user bases (combined). People check their mail, instant message, and browse through our content - they are an ENGAGED audience that we can and are going to do much better serving (and therefore, valuing and being valued by) in less constrained, artificial ways. And engagement counts.
1) We have a great brand.
People KNOW AOL. Early on, when I first started at AOL, I had argued we should milk the existing brand and move everything onto another marketing platform (WinAMP was my suggestion - think people would have checked out WinAMP Pictures, for example? Another thought I had was the "@aol" brand, as in "Radio@aol"; mostly I like the double entendre of "IM@aol" :D) - but I was wrong. There is huge, real value in a well known brand. That brand may stand for "Dumbed down Internet" to a lot of people today, but the equity in our brand, which is JUST as relevant today is it ever was, is about democratizing the Internet: taking transformational technologies and re-imagining them such that they are more readily consumptible, by novice and power users alike.
Moving that brand is a HUGE asset for us - and I'm encouraged because though we may not yet have a vision of where we should end up EXACTLY, we do know that its THATAWAY, and we've been moving steadily and strongly in that direction for the last 18 months.
[Continued in Part 2: "Why we won't win"]
Below are my speech notes from one of my All Hands presentations in the second half of last year (2005) - its a little out of context today, but I still thought it worth sharing.
Why AOL will win...
3) We have scale.
We have scale of audience, infrastructure, and marketing. 110M out of 160M or so Internet users in the US touches an AOL, Inc website (not counting TWX in this). And, our infrastructure is built to scale: no else could have pulled off Live8, for example - even Akamai's edge Network isn't in our capacity league. And its not just technical scale - we're a marketing powerhouse. We cycle [EDITED FOR PUBLIC CONSUMPTION] out of [EDITED FOR PUBLIC CONSUMPTION] households in the US through our acquisition channels EVERY YEAR. And that scale is relevant.
2) We have engagement.
More than half the Internet population in the U.S. launches one of our core desktop products alone - other than Windows, Office, and Solitaire (seriously) I don't think anything or anyone comes close to our usage. Our ENGAGED user base dwarfes the total OS X and Linux user bases (combined). People check their mail, instant message, and browse through our content - they are an ENGAGED audience that we can and are going to do much better serving (and therefore, valuing and being valued by) in less constrained, artificial ways. And engagement counts.
1) We have a great brand.
People KNOW AOL. Early on, when I first started at AOL, I had argued we should milk the existing brand and move everything onto another marketing platform (WinAMP was my suggestion - think people would have checked out WinAMP Pictures, for example? Another thought I had was the "@aol" brand, as in "Radio@aol"; mostly I like the double entendre of "IM@aol" :D) - but I was wrong. There is huge, real value in a well known brand. That brand may stand for "Dumbed down Internet" to a lot of people today, but the equity in our brand, which is JUST as relevant today is it ever was, is about democratizing the Internet: taking transformational technologies and re-imagining them such that they are more readily consumptible, by novice and power users alike.
Moving that brand is a HUGE asset for us - and I'm encouraged because though we may not yet have a vision of where we should end up EXACTLY, we do know that its THATAWAY, and we've been moving steadily and strongly in that direction for the last 18 months.
[Continued in Part 2: "Why we won't win"]
March 22, 2006
Microsoft: Developers, Developers, Developers (and Businesses)
This is probably not very insightful, but I realize these days that Microsoft doesn't make software for users (consumers). They haven't in a long time. I mean, sure somewhere in the vastness that is Microsoft they do (or at least, they think about it :P), but I mean the core stuff: Windows, Office, etc.
The X-Box is definitely in the consumer category, but Vista? .NET? IE? Office?
All for businesses first, consumers second, I'll contend.
Seems like kind of a self-fulfilling prophecy for Microsoft - make it easy for businesses and developers to build and deploy software on their platform(s), and these businesses will just continue to require Microsoft software to be deployed everywhere, which makes it easy to build and deploy software, rinse and repeat.
Its not a bad business (by any stretch of the imagination :)) - and if you think about it, they were "Computing 2.0" to the mainframe industry. It just took a while for the Web to catch up - it is, of course, all the wheel of reincarnation at work.
As I said, not really insightful, but now that I work at a consumer software company, that distinction seems more meaningful.
Here's a test on this thought: Would you say that .NET was a sucess or failure for Microsoft, and why?
Still, Microsoft Live is different.
They've got a long way to go, but its definitely for People. I think THIS is the big transition for Microsoft that the Web introduced: moving from business computing to truly personal computing thinking. And its not just a clone website - there is some very different thinking involved.
The X-Box is definitely in the consumer category, but Vista? .NET? IE? Office?
All for businesses first, consumers second, I'll contend.
Seems like kind of a self-fulfilling prophecy for Microsoft - make it easy for businesses and developers to build and deploy software on their platform(s), and these businesses will just continue to require Microsoft software to be deployed everywhere, which makes it easy to build and deploy software, rinse and repeat.
Its not a bad business (by any stretch of the imagination :)) - and if you think about it, they were "Computing 2.0" to the mainframe industry. It just took a while for the Web to catch up - it is, of course, all the wheel of reincarnation at work.
As I said, not really insightful, but now that I work at a consumer software company, that distinction seems more meaningful.
Here's a test on this thought: Would you say that .NET was a sucess or failure for Microsoft, and why?
Still, Microsoft Live is different.
They've got a long way to go, but its definitely for People. I think THIS is the big transition for Microsoft that the Web introduced: moving from business computing to truly personal computing thinking. And its not just a clone website - there is some very different thinking involved.
March 21, 2006
No longer speaking with my wife
The Internet is a strange place.
You'd think I'd be used to it by now, but I have to admit, I still get surprised at the stuff that emerges from the cracks of the Web.
For example, one of the Google queries that apparently led someone to my site?
"no longer speaking with my wife".
This site (http://sree.kotay.com) shows up, as of this writing, at #2 (on page 2, but still!!). Unless Google know something I don't, my wife and I are still on speaking terms. At least I haven't hit the "I'm Feeling Lucky" threshold... although this post probably won't help with regard to PageRank about this term (or with my wife, for that matter).
And Corey Lucier will burn for this.
You'd think I'd be used to it by now, but I have to admit, I still get surprised at the stuff that emerges from the cracks of the Web.
For example, one of the Google queries that apparently led someone to my site?
"no longer speaking with my wife".
This site (http://sree.kotay.com) shows up, as of this writing, at #2 (on page 2, but still!!). Unless Google know something I don't, my wife and I are still on speaking terms. At least I haven't hit the "I'm Feeling Lucky" threshold... although this post probably won't help with regard to PageRank about this term (or with my wife, for that matter).
And Corey Lucier will burn for this.
March 20, 2006
Web 2.0, pt 2: The Long Tail
In my last post on this topic, I made fun of people who use "Web 2.0", "AJAX", and "Mashup" too much, and then spent 5 or 6 paragraphs using it excessively.
...
[awkward pause]
Still, having a "pt 1" implies "pt 2" is coming, so I felt obligated to finish what I started - and I won't make it through this post either without wading waist deep into buzzword land :)
When last we spoke, I left a question on the table: Why did Search beat Directories? Its not a hard question, and more than a few commenters answered it more succintly (and better) than I probably would have. The short version is "Search is better", with assorted rationalizations. But the answer as to SPECIFICALLY why its better is better captured and explained, I feel, by a concept called "The Long Tail".
I won't dive into too much of the definition and details (feel free to read up) of it, but the core thought is this: The Internet (as always, IMHO) is fundamentally about altering the dynamics (economic and otherwise) of the 80-20 rule - what business folks call the rule of the "vital few and trivial many" (AKA the Pareto principle). Search won precisely because it doesn't pay off Pareto's principle.
...
[awkward pause]
Still, having a "pt 1" implies "pt 2" is coming, so I felt obligated to finish what I started - and I won't make it through this post either without wading waist deep into buzzword land :)
When last we spoke, I left a question on the table: Why did Search beat Directories? Its not a hard question, and more than a few commenters answered it more succintly (and better) than I probably would have. The short version is "Search is better", with assorted rationalizations. But the answer as to SPECIFICALLY why its better is better captured and explained, I feel, by a concept called "The Long Tail".
I won't dive into too much of the definition and details (feel free to read up) of it, but the core thought is this: The Internet (as always, IMHO) is fundamentally about altering the dynamics (economic and otherwise) of the 80-20 rule - what business folks call the rule of the "vital few and trivial many" (AKA the Pareto principle). Search won precisely because it doesn't pay off Pareto's principle.
Let's me explain that further.
The root of 20th century industrial economies of scale (particularly around distribution principles) is really captured in the idea that if, for example, you stock in your store the top 1,000 CDs, or top 5,000 books (or whatever the right numbers are here), you'll be poised to capture most, if not all, of the possible revenue/value. Adding more inventory starts to have diminishing return beyond that 20% of possible music or books, because that's what 80% of the people are looking for when they're out and about.
To put it more practically, 20% of your effort yields 80% of your results (and vice versa).
Sounds intuitive and head-noddy enough ([nodding] "why, yes, I knew that..."), but from the beginning, the promise of the Web has always been about shattering the Pareto principle.
Amazon, e-Bay, and yes, Google, have realized this promise for their core services. You can buy books you can't find anywhere else conveniently; you can purchase cheap (slightly used) merchandise you couldn't obtain anywhere else; And, you can locate websites and specific pages by Searching that you'd never figure out how to navigate to in a Directory, if it was even classified - heck, Searching is usually better than using a sitemap/directory on the website itself, even when you KNOW the right website.
And these companies derive SUBSTANTIAL benefit in doing so: you keep coming back as a customer.
If all they did was make available what you could get locally (physically or otherwise), it wouldn't really work - though they have to do that, too: an important point we'll touch on later. This "nichification" that the Web allows is real: turns out that you have to get to about 50% of the search terms to capture 80% of the volume - this is what they call "the Long Tail of Search".
So, when you hear terms like "Web as Platform" and "Participatory Web", the value to consumers is the same one that we see realized in the Long Tail of Search. Web 2.0 is about creating consumptable data services and applications that enable the Long Tail for Applications and Tools, in the same way that Amazon, E-Bay, and Google did for books, goods, and website navigation.
Said differently, Web 2.0 "MashUps" are about enabling "nichification" for applications: 5,000 micro-apps that serve 10,000 people, rather than one that serves a million.
Of course, if its really going to work, there's got to be more to it than just "[INSERT APP TYPE] + Google maps" and a fancy AJAX demo - we'll pick up this thread in my next post on Web 2.0 and connect it to more concrete business and consumer opportunities.
As I closed with in the final part of of my GPL 3 discussion, there are some dollars and sense issues (pun intended) that we should not overlook.
[Concluded in Part 3...]
March 19, 2006
GPL 3 Hole-y Wars, pt 3: Punchline
[Continued from Part 2]
Right now, pretty much every Internet company gets to enjoy the benefits of GPL software without any real concern about IP issues. And as long as major Open Source Software (OSS) projects stay away from GPL v3, it'll continue that way and won't force a choice for any commerical Internet venture (AOL included): whether to continue directly with the trunk or pick up a GPL 2 branch (also, there is no real notion that the licensing changes are retroactive).
Short term, it probably doesn't matter much, but it is interesting to track this increasing (potential) fracturing: more OSS licenses, more applications, more content sources, more devices, more browsers, more IP backbones(?) - more diversity, and not just at the infrastructure layer. It is, after all, what the Internet promised early on: many-to-many, microtargeted communications and expressions, of content, applications, tools, etc.
For a (short) while, with Internet Explorer dominating and the Bubble popping, things were going the other way.
The wierd part seems to be that no one is making any money except the big few. Everybody else's business model seems to be: get eyeballs (or better yet, even easier - just get buzz), and get bought. There may be a Long Tail (I'll explain this term a bit more in my very next post) usage-wise for the Internet, but the dollars seem to still follow the good old Pareto principle...
But I digress... (and am done on this topic already - yeesh).
Right now, pretty much every Internet company gets to enjoy the benefits of GPL software without any real concern about IP issues. And as long as major Open Source Software (OSS) projects stay away from GPL v3, it'll continue that way and won't force a choice for any commerical Internet venture (AOL included): whether to continue directly with the trunk or pick up a GPL 2 branch (also, there is no real notion that the licensing changes are retroactive).
Short term, it probably doesn't matter much, but it is interesting to track this increasing (potential) fracturing: more OSS licenses, more applications, more content sources, more devices, more browsers, more IP backbones(?) - more diversity, and not just at the infrastructure layer. It is, after all, what the Internet promised early on: many-to-many, microtargeted communications and expressions, of content, applications, tools, etc.
For a (short) while, with Internet Explorer dominating and the Bubble popping, things were going the other way.
The wierd part seems to be that no one is making any money except the big few. Everybody else's business model seems to be: get eyeballs (or better yet, even easier - just get buzz), and get bought. There may be a Long Tail (I'll explain this term a bit more in my very next post) usage-wise for the Internet, but the dollars seem to still follow the good old Pareto principle...
But I digress... (and am done on this topic already - yeesh).
March 18, 2006
GPL 3 Hole-y Wars, pt 2
[Continued from Part 1]
Interestingly, the original (few) versions of the GPL did not really imagine a web services world - and so there's been a major loophole for the last many years. If any GPL'ed software is being used on servers, the bits are never "shipped" to customers. Therefore, Internet companies are free to take any GPL software, modify and change it - derive SIGNIFICANT benefit from it - and NOT release the source code. Even if the functionality is identical to what you might provide with desktop software bits, you're free to keep the code "closed", so long as you don't ship the actual executable compiled from that code to the end user's desktop.
It sounds simple, but in practice this is somewhat subtle.
You can take the functionality of ANY such software, "remote" the functionality (i.e. have it run on a server instead of the local machine), and completely circumvent the GPL. Doesn't matter how much value that software created for your Internet business, or how much your improvements might help others. Taking an IP and business view, that means you can leverage the benefits of OSS (free labor, community review, improvements, etc.) without paying the capitalism "tax" that it might impose - so long as you don't care about installing desktop software.
No wonder Microsoft hates it :P
Part of the rationale for the new version is to attempt and rectify this loophole. I'm a little worried about the "... and then some" provisions they're including - very wierd some of the requirements version 3 includes (about source distribution requirements among other things). It'll be interesting to see which major GPL open source projects (Linux, Apache, etc.) switch to the GPL v3, and what implications this has for the Web and its standards.
If any of the major OSS web infrastructure projects does adopt it, I predict we'll see some MAJOR fracturing over time, as commercial companies fork from the previous GPL'ed versions. If nothing else, we would get a chance to see who thinks with their wallet - but pretends they don't.
Linus Torvalds, of Linux fame, does not like GPL 3, at least in the case of the Linux kernel itself (though I suspect this has more to do with the odd requirements than the attempt to close the web services loophole).
Interestingly, the original (few) versions of the GPL did not really imagine a web services world - and so there's been a major loophole for the last many years. If any GPL'ed software is being used on servers, the bits are never "shipped" to customers. Therefore, Internet companies are free to take any GPL software, modify and change it - derive SIGNIFICANT benefit from it - and NOT release the source code. Even if the functionality is identical to what you might provide with desktop software bits, you're free to keep the code "closed", so long as you don't ship the actual executable compiled from that code to the end user's desktop.
It sounds simple, but in practice this is somewhat subtle.
You can take the functionality of ANY such software, "remote" the functionality (i.e. have it run on a server instead of the local machine), and completely circumvent the GPL. Doesn't matter how much value that software created for your Internet business, or how much your improvements might help others. Taking an IP and business view, that means you can leverage the benefits of OSS (free labor, community review, improvements, etc.) without paying the capitalism "tax" that it might impose - so long as you don't care about installing desktop software.
No wonder Microsoft hates it :P
Part of the rationale for the new version is to attempt and rectify this loophole. I'm a little worried about the "... and then some" provisions they're including - very wierd some of the requirements version 3 includes (about source distribution requirements among other things). It'll be interesting to see which major GPL open source projects (Linux, Apache, etc.) switch to the GPL v3, and what implications this has for the Web and its standards.
If any of the major OSS web infrastructure projects does adopt it, I predict we'll see some MAJOR fracturing over time, as commercial companies fork from the previous GPL'ed versions. If nothing else, we would get a chance to see who thinks with their wallet - but pretends they don't.
Linus Torvalds, of Linux fame, does not like GPL 3, at least in the case of the Linux kernel itself (though I suspect this has more to do with the odd requirements than the attempt to close the web services loophole).
[To be concluded in part 3...]
March 17, 2006
GPL 3 Hole-y Wars, pt 1
The Free Software Foundation(FSF) is working on a new version of the GNU Public License (GPL) for software. As we all know, the intent of the GPL is to DESTROY INTELLECTUAL PROPERTY - ooooh oohoho!!!
Just kidding.
The intent of the GPL is to make software "Free". "Free" can mean a lot of things - in this context, its (mostly) about being permanently "Free" to modify (which means, you should always have access to the source code). Under the GPL, you can't take software that was released as "Free" and in any way make it not "Free". Critics argue this makes it "viral", from an Intellectual Property (IP) perpsective. If you, as a developer, use GPL software in your software, you can't ship it your customers without also releasing the source code, including your improvements - that you must provide at no cost.
The philosophical point is well summed up by a common FSF mantra: "Free" as in speech, not "Free" as in beer. Its not about just offering the software for free, per se.
Pretty radical.
Still, no one's making anyone use it. The theory is really simple: if you derived benefit from GPL software (that YOU got for FREE, remember), and you make enhancements or changes, then those changes should be contributed back to the community that gave you that leg-up in the first place. Its a fairly progressive socialistic mindset, and propenents like to refer to this as "copyleft" thinking (as opposed to "copyright").
The GPL is a popular license under which many Open Source Software (OSS) projects release their, um, releases (and therefore source code). It recognizes as its core precept that we all stand on the shoulders of giants.
[Continued in Part 2...]
Just kidding.
The intent of the GPL is to make software "Free". "Free" can mean a lot of things - in this context, its (mostly) about being permanently "Free" to modify (which means, you should always have access to the source code). Under the GPL, you can't take software that was released as "Free" and in any way make it not "Free". Critics argue this makes it "viral", from an Intellectual Property (IP) perpsective. If you, as a developer, use GPL software in your software, you can't ship it your customers without also releasing the source code, including your improvements - that you must provide at no cost.
The philosophical point is well summed up by a common FSF mantra: "Free" as in speech, not "Free" as in beer. Its not about just offering the software for free, per se.
Pretty radical.
Still, no one's making anyone use it. The theory is really simple: if you derived benefit from GPL software (that YOU got for FREE, remember), and you make enhancements or changes, then those changes should be contributed back to the community that gave you that leg-up in the first place. Its a fairly progressive socialistic mindset, and propenents like to refer to this as "copyleft" thinking (as opposed to "copyright").
The GPL is a popular license under which many Open Source Software (OSS) projects release their, um, releases (and therefore source code). It recognizes as its core precept that we all stand on the shoulders of giants.
[Continued in Part 2...]
March 16, 2006
Replace with "flogging"?
Some avid readers pointed out that I tend to have a lot of misspellings in my blog posts. Clearly some people have too much time on their hands.
I attribute some amount of that perception to wierd affectations of mine. For example, I prefer "behaviour" to "behavior" and "hilite" to "hilight"; I also enjoy using semi-colons (and overusing parenthetical comments). But mostly I'd guess its because I never use a spell checker :)
I attribute some amount of that perception to wierd affectations of mine. For example, I prefer "behaviour" to "behavior" and "hilite" to "hilight"; I also enjoy using semi-colons (and overusing parenthetical comments). But mostly I'd guess its because I never use a spell checker :)
I did use the spell checker provided by my blogging tool early on, but I stopped as soon as I noticed that "blogging" wasn't in its dictionary. It suggested I use the term "flogging" instead.
Perhaps it was trying to tell me something.
In any case, I suppose I could use a word processor, or simply train the aformentioned spell checker with the words that I tend to use.
Honestly though, when it comes to flogging, I'm OK with a being a tad sloppy. My wife calls it "laziness"; I tend to think of it as "economy of motion".
Ta-mAY-toe/Ta-mAH-toe?
March 14, 2006
Web 2.0, pt 1: AJAX, Mash-ups, and Search
Updated: Continued in Part 2
I stumbled upon a realization the other day- probably obvious to many already- the latest AJAX (of at least the first half of 2006) is "Mash-ups".
The idea, term, and even demos, have been around for a while, but from what I can tell, like AJAX and Web 2.0, "Mash-up" is a term that is on track to quickly become overused into meaninglessness. (If you don't know the term yet - though you probably do - you're SOOOO not cool. Of course, if you DO know it, and use it regularly in sentences, well, you are ALSO so not cool :P - at least to developers).
AJAX really refers to a specific set of design patterns within the larger context of DHTML (scripting + HTML) authoring, but it has become a proxy for "runs like a desktop app, RIGHT IN YOUR BROWSER!" (that noise you hear is the pitter-patter of over enthused VCs). And now we have further confusing bastardizations like "AJAX-y" - meaning its not using XMLHTTPRequest() per se, but looks like the type of applications that were the initial poster children for the AJAX pattern.
Web 2.0 is the term everyone users to refer to the next generation of Internet applications and services. Given that "Web 1.0" brought us "Business 2.0", I'm expecting "Business 3.0" to GM shortly (fixes a few compatibility bugs; better perfomance and featuring a streamlined user interface!).
"AJAX" and "Mash-ups" are definitionally within the Web 2.0 bubble, and though they're all used and overused terms, there are a few specific precepts to Web 2.0 that are worth distinctly understanding. That is to say, its not all hype.
People tend to toss around a lot of terms when they talk about Web 2.0, including:
- Web as Platform
- Harnessing Collective Intelligence (AKA the wisdom of crowds)
- Rich User Experiences
- Lightweight user interfaces, development models, AND business models
- Participatory Web
The ambiguity in deciphering exactly what all this means is probably at least partially to blame for the low signal-to-noise ratio with Web 2.0's colloquial usage.
I'll cover what I think it means in my next post on this topic, but will leave you with this (rhetorical) question: Why did Search beat Directories (and I'll argue content portals) as the primary mode of web navigation?
I stumbled upon a realization the other day- probably obvious to many already- the latest AJAX (of at least the first half of 2006) is "Mash-ups".
The idea, term, and even demos, have been around for a while, but from what I can tell, like AJAX and Web 2.0, "Mash-up" is a term that is on track to quickly become overused into meaninglessness. (If you don't know the term yet - though you probably do - you're SOOOO not cool. Of course, if you DO know it, and use it regularly in sentences, well, you are ALSO so not cool :P - at least to developers).
AJAX really refers to a specific set of design patterns within the larger context of DHTML (scripting + HTML) authoring, but it has become a proxy for "runs like a desktop app, RIGHT IN YOUR BROWSER!" (that noise you hear is the pitter-patter of over enthused VCs). And now we have further confusing bastardizations like "AJAX-y" - meaning its not using XMLHTTPRequest() per se, but looks like the type of applications that were the initial poster children for the AJAX pattern.
Web 2.0 is the term everyone users to refer to the next generation of Internet applications and services. Given that "Web 1.0" brought us "Business 2.0", I'm expecting "Business 3.0" to GM shortly (fixes a few compatibility bugs; better perfomance and featuring a streamlined user interface!).
"AJAX" and "Mash-ups" are definitionally within the Web 2.0 bubble, and though they're all used and overused terms, there are a few specific precepts to Web 2.0 that are worth distinctly understanding. That is to say, its not all hype.
People tend to toss around a lot of terms when they talk about Web 2.0, including:
- Web as Platform
- Harnessing Collective Intelligence (AKA the wisdom of crowds)
- Rich User Experiences
- Lightweight user interfaces, development models, AND business models
- Participatory Web
The ambiguity in deciphering exactly what all this means is probably at least partially to blame for the low signal-to-noise ratio with Web 2.0's colloquial usage.
I'll cover what I think it means in my next post on this topic, but will leave you with this (rhetorical) question: Why did Search beat Directories (and I'll argue content portals) as the primary mode of web navigation?
March 13, 2006
UI Inflections, pt 1: ClearType, IE 7, and Boxely
Microsoft has decided to enable ClearType by default in Internet Explorer 7 (Beta 2), independent of whatever the user has selected as his/her OS setting. Its not clear if this will remain the case when they finally release IE 7, but the decision seems to have caused a bit of confusion.
For what its worth, I agree with Bill Hill about the value of good antialias text rendering. Some argue it just makes text blurry, and that it is strictly a benefit ONLY for visual appearance (i.e. it looks better, but is harder to read, AKA "form over function"). I don't agree, though I think that you indeed sacrifice letter quality to improve word quality, and therefore, increase readability.
We went through almost exactly the same thing with Boxely, inside AOL. For a variety of technology driven reasons (historical, patent-issues, alpha channel problems, etc.) we ended up with our own text display engine in Boxely - in which we do our own font rendering, at a pixel level. It is antialiased, always, regardless of OS setting, and the Boxely team caught a lot of flack for it, but it hasn't been a big deal in the real world.
I think it improves both the form and function of our OCP apps. Or maybe Bill and I just drank too much of the same cool-aid...
Still, it DOES kind of suck to not respect the OS setting. More and more it makes you wonder about the value of the no-longer-very-unified user experiences that modern GUIs were supposed to provide.
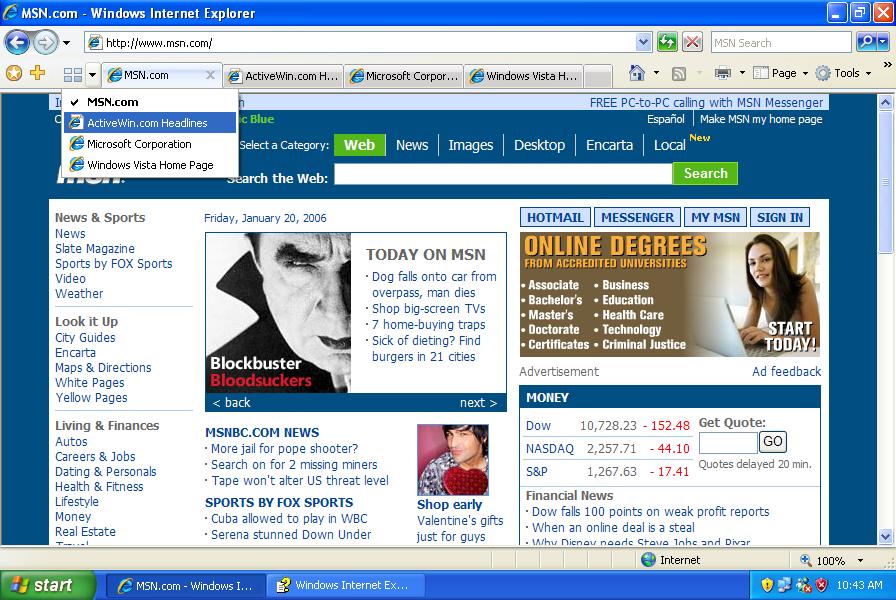
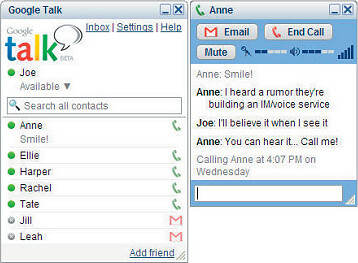
Just perusing the look and feel of the latest AIM Triton, MSN Messenger 8, Microsoft Office 12, Picasa 2, Adobe Lightroom, IE 7, Google Talk...
Hmm - so much for a consistent "look and feel"...
There's a trend here clearly - I think we're at a major inflection point with regard to user interfaces for applications that Vista will accelerate.
Part of the question is: Is this a good thing? Does it matter anymore?
I'm not sure it does - exposition forthcoming in part 2.
For what its worth, I agree with Bill Hill about the value of good antialias text rendering. Some argue it just makes text blurry, and that it is strictly a benefit ONLY for visual appearance (i.e. it looks better, but is harder to read, AKA "form over function"). I don't agree, though I think that you indeed sacrifice letter quality to improve word quality, and therefore, increase readability.
We went through almost exactly the same thing with Boxely, inside AOL. For a variety of technology driven reasons (historical, patent-issues, alpha channel problems, etc.) we ended up with our own text display engine in Boxely - in which we do our own font rendering, at a pixel level. It is antialiased, always, regardless of OS setting, and the Boxely team caught a lot of flack for it, but it hasn't been a big deal in the real world.
I think it improves both the form and function of our OCP apps. Or maybe Bill and I just drank too much of the same cool-aid...
Still, it DOES kind of suck to not respect the OS setting. More and more it makes you wonder about the value of the no-longer-very-unified user experiences that modern GUIs were supposed to provide.
Just perusing the look and feel of the latest AIM Triton, MSN Messenger 8, Microsoft Office 12, Picasa 2, Adobe Lightroom, IE 7, Google Talk...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hmm - so much for a consistent "look and feel"...
There's a trend here clearly - I think we're at a major inflection point with regard to user interfaces for applications that Vista will accelerate.
Part of the question is: Is this a good thing? Does it matter anymore?
I'm not sure it does - exposition forthcoming in part 2.
March 12, 2006
Why did the chicken cross the Moebius strip?
To get to the other .... um... hunh...
:)
Last (and short) browser-centric post from me for a while (enough about Firefox vs. Internet Explorer already:P). Anyhoo, some interesting comments from Joe Wilcox of Jupiter Research - it basically covers the business rationale for AOL having its own browser (50,000 foot view).
It's nice that people are starting to notice that AOL is getting to the other side.
:)
Last (and short) browser-centric post from me for a while (enough about Firefox vs. Internet Explorer already:P). Anyhoo, some interesting comments from Joe Wilcox of Jupiter Research - it basically covers the business rationale for AOL having its own browser (50,000 foot view).
It's nice that people are starting to notice that AOL is getting to the other side.
To "Install" or not to "Install"?
Updated: I should mention that Microsoft has released a similar feature in the latest IE 7 betas (RSS Screensaver). It doesn't appear to me that either company was particularly influenced by the other in this regard.
While we're on the subject of (browsers and) AOL Explorer: there's a new beta available (version 1.5 - its an early beta, so no promises :)).
It introduces a few (new) nice features, in clean, clutter-free way. In particular, I like the the RSS Screensaver - its one-click activation, and actually pretty cool - Not earth-shattering, or anything, but nice. Just click "Install Screensaver" in the "Feeds" panel (on the left sidebar of the browser) - I think you'll be pleased at the utility and value, especially if you're on Broadband.
I find, though, the label of the button to be all wrong - confusing AND misleading (and WRONG :)). In this case, the Screensaver software is already on the box (as a part of the AOL Explorer install), it just gets set as your current screensaver.
And although the button is on the "Feeds" panel I don't think the action is clear, contextually.
I'd have preferred to have it be a checkbox that said "Show my Feeds as a Screensaver." (or something; and then have it work much like the "Check if default browser..." feature works).
So why does it say "Install Screensaver"?
Well, we felt that "Install Screensaver" best captured the percieved literal (if there is such a concept) result of the action. Especially with all the (justified) sensitivity to Spyware, etc., we didn't want to make it feel like we were hijacking anything on the end user's machine and I agree with the rationale.
Still - I feel like we've sacrificed clarity in the name of user advocacy. It may feel more true, but I think its less right, and less helpful.
The internal debate about this centered on this question: what does "installation" mean anymore?
Surprisingly, we run into this a lot - especially in a rights obsessed world - for advocacy, privacy, and legal reasons. The heart of the question, I think is: what separates applications from content? (The implied idea, in this case, being that apps require install; content does not - there are other issues about distribution rights that bite us in this regard).
Is HTML "application" or "content"? Does JavaScript that gets downloaded, run and cached by your browser count as "code"? What about a game level for Doom 3? Does that require "install"?
Easy: a webpage is small, so no install required, and a Doom 3 level is big, and so requires an install.
But, keep in mind the RSS screensaver in AOL Explorer (executable code) is smaller than the Amazon.com homepage - do we really mean to imply we can skip the "Install" moniker for small applications? Probably not - Spyware can be written to be QUITE small - usually is, in fact.
Perhaps, then, "install" is for stuff that is COMPILED executable code? But what about a Java applet? Or a dot NET application the runs on the Microsoft CLR? Or Flash Applets (which indeed compile Actionscript to bytecodes)? Aha - perhaps it needs to be NATIVE executable code ... but, (to continue the abstraction) what if you're running in a Virtual PC session? Are you really "installing" anything in that case? After all, its ALL just "content" to a virtual machine.
Maybe the distinction is that if it "touches" anything on the OS, and by extension the "physical" PC, (i.e. violates some preconcieved notion of "sandboxing") then it is not content - its an application, and therefore requires install?
I guess for now, "Install" is like "Pornography" - I can't tell you what it is, but I know it when I see it.
And in the meantime, we (software industry "we") can continue to confuse our users in the name of protecting them.
While we're on the subject of (browsers and) AOL Explorer: there's a new beta available (version 1.5 - its an early beta, so no promises :)).
It introduces a few (new) nice features, in clean, clutter-free way. In particular, I like the the RSS Screensaver - its one-click activation, and actually pretty cool - Not earth-shattering, or anything, but nice. Just click "Install Screensaver" in the "Feeds" panel (on the left sidebar of the browser) - I think you'll be pleased at the utility and value, especially if you're on Broadband.
I find, though, the label of the button to be all wrong - confusing AND misleading (and WRONG :)). In this case, the Screensaver software is already on the box (as a part of the AOL Explorer install), it just gets set as your current screensaver.
And although the button is on the "Feeds" panel I don't think the action is clear, contextually.
I'd have preferred to have it be a checkbox that said "Show my Feeds as a Screensaver." (or something; and then have it work much like the "Check if default browser..." feature works).
So why does it say "Install Screensaver"?
Well, we felt that "Install Screensaver" best captured the percieved literal (if there is such a concept) result of the action. Especially with all the (justified) sensitivity to Spyware, etc., we didn't want to make it feel like we were hijacking anything on the end user's machine and I agree with the rationale.
Still - I feel like we've sacrificed clarity in the name of user advocacy. It may feel more true, but I think its less right, and less helpful.
The internal debate about this centered on this question: what does "installation" mean anymore?
Surprisingly, we run into this a lot - especially in a rights obsessed world - for advocacy, privacy, and legal reasons. The heart of the question, I think is: what separates applications from content? (The implied idea, in this case, being that apps require install; content does not - there are other issues about distribution rights that bite us in this regard).
Is HTML "application" or "content"? Does JavaScript that gets downloaded, run and cached by your browser count as "code"? What about a game level for Doom 3? Does that require "install"?
Easy: a webpage is small, so no install required, and a Doom 3 level is big, and so requires an install.
But, keep in mind the RSS screensaver in AOL Explorer (executable code) is smaller than the Amazon.com homepage - do we really mean to imply we can skip the "Install" moniker for small applications? Probably not - Spyware can be written to be QUITE small - usually is, in fact.
Perhaps, then, "install" is for stuff that is COMPILED executable code? But what about a Java applet? Or a dot NET application the runs on the Microsoft CLR? Or Flash Applets (which indeed compile Actionscript to bytecodes)? Aha - perhaps it needs to be NATIVE executable code ... but, (to continue the abstraction) what if you're running in a Virtual PC session? Are you really "installing" anything in that case? After all, its ALL just "content" to a virtual machine.
Maybe the distinction is that if it "touches" anything on the OS, and by extension the "physical" PC, (i.e. violates some preconcieved notion of "sandboxing") then it is not content - its an application, and therefore requires install?
I guess for now, "Install" is like "Pornography" - I can't tell you what it is, but I know it when I see it.
And in the meantime, we (software industry "we") can continue to confuse our users in the name of protecting them.
March 9, 2006
Origami and the dangers of careless blogging
I almost posted about Microsoft's Origami project a few weeks ago - there were rumours making the rounds and somehow I got the impression it had been announced. Fortunately, in looking for a link to include, I found out it had NOT. That would have been a definite NDA violation.
Oops.
I wonder what would have happened? I mean, all the rumour sites were pretty much dead-on (and the video gives it away). Oh well, probably best I don't find out.
As to the device itself, it may be a little underwhelming in the "gee-whiz-new-feature" department, but I have to admit, I want one. I think it will do OK in the marketplace - it may even redefine the ultra-portable segment. Keys to success will be: horsepower, price, battery life, and the usability of the keyboard.
The stylus/Tablet PC aspect is still under-imagined and over valued, in my view. The last great input device to succeed (the mouse) required a a complete re-imagining of the human-computer-interface. I think touch screen computing needs to signigicantly evolve the metaphors of interaction - just being an awkward mouse doesn't do much for me (or anyone else, I think).
All in all, from what I've seen, I don't think this first incarnation of Origami will be quite the runaway revolution Microsoft hopes for - I think the idea is that it will become the portable PERSONAL computing device: One for everybody in the family! It will be your portable digital media hub! - like we've not heard all of these ideas before.
Still, I want one - probably not a bad sign, especially for "version 1.0" (or maybe 2.0, if you think about Tablet PCs as 1.0 - so one more generation to go...)
And definitely a sign of the future...
...And the past - I think Origami might be the first real "karmic" successor to the Newton. Palm, Treo, and its ilk of PDA/cel-phones/whatever, I think of as more squarely in the consumer electronics category - and steps away from the general computing opportunities that Origami represents.
Oops.
I wonder what would have happened? I mean, all the rumour sites were pretty much dead-on (and the video gives it away). Oh well, probably best I don't find out.
As to the device itself, it may be a little underwhelming in the "gee-whiz-new-feature" department, but I have to admit, I want one. I think it will do OK in the marketplace - it may even redefine the ultra-portable segment. Keys to success will be: horsepower, price, battery life, and the usability of the keyboard.
The stylus/Tablet PC aspect is still under-imagined and over valued, in my view. The last great input device to succeed (the mouse) required a a complete re-imagining of the human-computer-interface. I think touch screen computing needs to signigicantly evolve the metaphors of interaction - just being an awkward mouse doesn't do much for me (or anyone else, I think).
All in all, from what I've seen, I don't think this first incarnation of Origami will be quite the runaway revolution Microsoft hopes for - I think the idea is that it will become the portable PERSONAL computing device: One for everybody in the family! It will be your portable digital media hub! - like we've not heard all of these ideas before.
Still, I want one - probably not a bad sign, especially for "version 1.0" (or maybe 2.0, if you think about Tablet PCs as 1.0 - so one more generation to go...)
And definitely a sign of the future...
...And the past - I think Origami might be the first real "karmic" successor to the Newton. Palm, Treo, and its ilk of PDA/cel-phones/whatever, I think of as more squarely in the consumer electronics category - and steps away from the general computing opportunities that Origami represents.
March 8, 2006
Firefox v. IE: an AOL View, pt 3
[continued... read part 2 first]
b) Firefox is more standards compliant
Again, yes.
Unfortunately, I think this is largely (though not entirely) a non-factor for two reasons:
(1) Our priority is to our customers and consumers first, the industry second. Making things easier for developers ranks below making them WORK for our members. Remember that all of our efforts succeed only on the backs of their clicks.
(2) Compatibility is FAR more important than compliance.
Oh wait, that’s the same point.
Forunately, Microsoft is doing a lot to improve IE’s compliance in this regard, though they are (somewhat) limited by the higher goal of broad compatibility. And there's part of the benefit for AOL - let the OS take care of the guts - we'll do the application. If we did a Mac version of AOL Explorer, we'd use WebKit (which powers Apple's Safari browser).
Its not clear what "standards" means from a consumer context - I'd argue it means "compatibility".
c) Firefox provides a better experience/is more powerful
Note that I did NOT say that Firefox is faster or leaner or faster or leaner. It is faster at some stuff, but IE performs better at others. Over time, though, I do expect the balance to tip more in favor of Firefox, if Microsoft can't stop the slide of developers in particular - there will be a natural tendency to optimize for the platform on which you are developing...
...But I digress...
If we’re not talking about security, standards, or speed, we’re no longer talking about the browsing ENGINE - we’re now discussing the browser as a PRODUCT, when we say "better experience/more powerful".
I mean, if you were REALLY serious about security, standards, or speed in your browsing engine - why, you’d be advocating Opera. I know I did.
Its free.
And cross-platform.
And light-weight.
And more secure than Firefox
(i.e. there are degrees of security: its not a black and white issue)
Unfortunately, the code's not available (we asked :)), and there are other issues, as well - but if these are the things that move you, YOU should go get it!
But in terms of IE vs. Firefox, that leaves me with...
d) Firefox is cooler
Indubitably. No arguments there. Heck, its practically a religion - though that comes with its own baggage. And there is a wonderful and valid romanticism to its story.
But we’re AOL - the moment we touch it, its not really that cool, is it? We have to compete on features and the product itself.
Now, Firefox DOES has some very nice features, both novel (new) and those appropriated from competitors/predecessors (enhancements), much like any good product.
And perusing the FEATURED feature list from their homepage:
- A Better Web Experience
- Faster Browsing
- Automatic Updates
- Tabbed Browsing
- Improved Pop-up Blocking
- Integrated Search
- Stronger Security
- Clear Private Data
- Live Bookmarks
- etc.
Additionally, the Mozilla Foundation has done a fantastic job with the developer community and extensions, generally, and I hope that we have the scale to entice developers at that level.
But that aside... Hmm... that list could be the marketing pitch for pretty much every browser EXCEPT Internet Explorer...
Oh wait, never mind. [IE 7 link]
It'd be nice if there were even more relevant features you could provide, if you had a nice browser whose destiny and experience you controlled - value you could deliver to you customers, and recirculation you could generate within your network of services...
Oh wait, never mind. [AOL Explorer 1.5 beta link]
OK, I'm being a little facile - but whatever you think of our desire to do our own browser, and whatever you may think of its feature set, that has little bearing on our choice of underlying browsing technology.
Yes, Firefox has some really good product features. I think we've done OK in that regard, too.
So... Punchline:
What I'm getting to is this: when I measure on any axis that I think really matters to end users (other than the "chase the buzz" one... :P), choice of browsing engine is not nearly as important (as always, IMHO) as the features and benefits the product itself delivers - as opposed to the display technology.
[It DOES however, matter to developers - though one could argue a one browser world would be nice for developers; perhaps its just a debate of WHICH browser it should be? :P]
Firefox's browser engine, though more robust, is also still young. As it stabilizes (development-wise) and matures a bit (on top of XULRunner for example) we'll be watching. And if, over time, the fundamentals of browsing ENGINES changes meaningfully, then perhaps we'll revisit and revise our choice here. Fortunately, our platform work makes even an engine switch (relatively) straightforward - AOL Explorer really is a browser "skin" more than a "browser" in the usual sense...
For now, though, compatibility (and alignment with the OS) trumps the other percieved benefits. And that really is a big deal.
Compatibility is pretty much the biggest reason I (personally) kept giving up on Opera, back in the day - not enough sites worked. Firefox has done a better job at both evangelism and balancing the tradeoffs, and more and more, with Safari on the Mac and Firefox everywhere else ... well, we'll see. I wish them well.
Microsoft has made a (pretty good) business and priority of delivering robust APIs and services - and betting against them on technology infrastructure just doesn't seem to have a compelling business case behind it - for the company, or (more importantly) for our users (for example, its nice that they don't have to "import" favorites - their favorites are just their favorites). And whatever the reason, Microsoft is really working hard to make IE 7 a lot better for web developers.
[ALTHOUGH, there is a bit of karma that those of you who both hate Microsoft (and maybe AOL) but love Firefox (I know: what an ODD overlap!) will find appropriate. It's currently at play in our relationship with them with regards to the development of IE 7 features -I'll share that in a future post, at some point, as I've rambled on waaaay too long already.]
All that said (and all snarkiness aside), I should reiterate that I really do believe that Firefox is a fine product that fully deserves the accolades it has received. It is genuinely good for the industry and end users alike to have it continue to have it do well in the marketplace.
I just don't think its browsing engine makes sense for AOL Explorer.
b) Firefox is more standards compliant
Again, yes.
Unfortunately, I think this is largely (though not entirely) a non-factor for two reasons:
(1) Our priority is to our customers and consumers first, the industry second. Making things easier for developers ranks below making them WORK for our members. Remember that all of our efforts succeed only on the backs of their clicks.
(2) Compatibility is FAR more important than compliance.
Oh wait, that’s the same point.
Forunately, Microsoft is doing a lot to improve IE’s compliance in this regard, though they are (somewhat) limited by the higher goal of broad compatibility. And there's part of the benefit for AOL - let the OS take care of the guts - we'll do the application. If we did a Mac version of AOL Explorer, we'd use WebKit (which powers Apple's Safari browser).
Its not clear what "standards" means from a consumer context - I'd argue it means "compatibility".
c) Firefox provides a better experience/is more powerful
Note that I did NOT say that Firefox is faster or leaner or faster or leaner. It is faster at some stuff, but IE performs better at others. Over time, though, I do expect the balance to tip more in favor of Firefox, if Microsoft can't stop the slide of developers in particular - there will be a natural tendency to optimize for the platform on which you are developing...
...But I digress...
If we’re not talking about security, standards, or speed, we’re no longer talking about the browsing ENGINE - we’re now discussing the browser as a PRODUCT, when we say "better experience/more powerful".
I mean, if you were REALLY serious about security, standards, or speed in your browsing engine - why, you’d be advocating Opera. I know I did.
Its free.
And cross-platform.
And light-weight.
And more secure than Firefox
(i.e. there are degrees of security: its not a black and white issue)
Unfortunately, the code's not available (we asked :)), and there are other issues, as well - but if these are the things that move you, YOU should go get it!
But in terms of IE vs. Firefox, that leaves me with...
d) Firefox is cooler
Indubitably. No arguments there. Heck, its practically a religion - though that comes with its own baggage. And there is a wonderful and valid romanticism to its story.
But we’re AOL - the moment we touch it, its not really that cool, is it? We have to compete on features and the product itself.
Now, Firefox DOES has some very nice features, both novel (new) and those appropriated from competitors/predecessors (enhancements), much like any good product.
And perusing the FEATURED feature list from their homepage:
- A Better Web Experience
- Faster Browsing
- Automatic Updates
- Tabbed Browsing
- Improved Pop-up Blocking
- Integrated Search
- Stronger Security
- Clear Private Data
- Live Bookmarks
- etc.
Additionally, the Mozilla Foundation has done a fantastic job with the developer community and extensions, generally, and I hope that we have the scale to entice developers at that level.
But that aside... Hmm... that list could be the marketing pitch for pretty much every browser EXCEPT Internet Explorer...
Oh wait, never mind. [IE 7 link]
It'd be nice if there were even more relevant features you could provide, if you had a nice browser whose destiny and experience you controlled - value you could deliver to you customers, and recirculation you could generate within your network of services...
Oh wait, never mind. [AOL Explorer 1.5 beta link]
OK, I'm being a little facile - but whatever you think of our desire to do our own browser, and whatever you may think of its feature set, that has little bearing on our choice of underlying browsing technology.
Yes, Firefox has some really good product features. I think we've done OK in that regard, too.
So... Punchline:
What I'm getting to is this: when I measure on any axis that I think really matters to end users (other than the "chase the buzz" one... :P), choice of browsing engine is not nearly as important (as always, IMHO) as the features and benefits the product itself delivers - as opposed to the display technology.
[It DOES however, matter to developers - though one could argue a one browser world would be nice for developers; perhaps its just a debate of WHICH browser it should be? :P]
Firefox's browser engine, though more robust, is also still young. As it stabilizes (development-wise) and matures a bit (on top of XULRunner for example) we'll be watching. And if, over time, the fundamentals of browsing ENGINES changes meaningfully, then perhaps we'll revisit and revise our choice here. Fortunately, our platform work makes even an engine switch (relatively) straightforward - AOL Explorer really is a browser "skin" more than a "browser" in the usual sense...
For now, though, compatibility (and alignment with the OS) trumps the other percieved benefits. And that really is a big deal.
Compatibility is pretty much the biggest reason I (personally) kept giving up on Opera, back in the day - not enough sites worked. Firefox has done a better job at both evangelism and balancing the tradeoffs, and more and more, with Safari on the Mac and Firefox everywhere else ... well, we'll see. I wish them well.
Microsoft has made a (pretty good) business and priority of delivering robust APIs and services - and betting against them on technology infrastructure just doesn't seem to have a compelling business case behind it - for the company, or (more importantly) for our users (for example, its nice that they don't have to "import" favorites - their favorites are just their favorites). And whatever the reason, Microsoft is really working hard to make IE 7 a lot better for web developers.
[ALTHOUGH, there is a bit of karma that those of you who both hate Microsoft (and maybe AOL) but love Firefox (I know: what an ODD overlap!) will find appropriate. It's currently at play in our relationship with them with regards to the development of IE 7 features -I'll share that in a future post, at some point, as I've rambled on waaaay too long already.]
All that said (and all snarkiness aside), I should reiterate that I really do believe that Firefox is a fine product that fully deserves the accolades it has received. It is genuinely good for the industry and end users alike to have it continue to have it do well in the marketplace.
I just don't think its browsing engine makes sense for AOL Explorer.
March 7, 2006
Firefox v. IE: an AOL View, pt 2
Read part 1.
Before I continue down this road I should point out that (a) I’m not answering why AOL is bothering to make a browser at all - that’s a different discussion for a different day - I’m answering why I think IE is a better choice than anything (currently) from the Mozilla Foundation as the underyling engine for that browser, and (b) this was a question that was asked even by our CEO, so I'm really not just rationalizing ex post facto :)
In my last post on this topic, I leveled a few scathing accusations against Firefox (vs. Internet Explorer), including:
- Firefox is safer/more secure
- Firefox is more standards compliant
- Firefox provides a better experience/is more powerful
- Firefox is cooler
So given all that, how is it possible that I think IE is a substantially better choice than Firefox (Mozilla/Gecko/etc. - I'm using Firefox as a proxy here) for our web browser, AOL Explorer?
Its always possible that we at AOL are just evil (and stupid :)). Or, perhaps its not so much THAT, as it is that we're part of a vast conspiracy to keep you down - that we are, in fact, "the man".
Let's parse this a little bit further to see where it leads us.
a) Firefox is safer/more secure
While it's true that there's been some noise over time about the number of security vulnerabilities in IE vs. Firefox, as well as the classification of those bugs, I think its just that: noise. I'll stipulate that, more likely than not - by any objective measure - Firefox has a safer browsing engine than IE.
There was, for example, a test comparing unpatched versions of each browser that demonstrated that Firefox is 21 times safer than IE (or to put that in less-alarmist language: unpatched IE had about a 1.52% greater rate of infection).
I'll posit, however, that Firefox (and its derivatives) are not safer in a meaningful way for consumers.
I say this for two primary reasons:
(1) Opportunity set.
Certainly the targeting opportunity is a factor (a key point: you'll note Firefox was NOT zero) - the idea being that Firefox users don't get targeted as much, because there are easier, broader pickings (*cough*IE *cough*AOL). How big a factor this is is difficult to say, but its hard to discount completely. And although I agree that the Firefox team has been (much more) diligent in patching the holes, new ones get found regularly.
I mention this because throwing our user base against this codebase would certainly create opportunity and incentive for the malicious. (Updated: for example this report)
(2) Third party technologies.
While Firefox may not support ActiveX (and much is made of this), it does support NATIVE plug-ins and extensions, including Flash, Java, Quicktime, Windows Media Player, etc. So it is subject to not only to its own (potential) problems, but to those of external vendors and technologies, much like Internet Explorer: Firefox just doesn't have as MANY (yet).
My main point on security, though, is slightly sideways: you're going to have MEANINGFULLY less infections and problems on your computer (viruses, spyware, etc.) only by having actual security software installed on the box: Antivirus, Antispyware, Firewall, et al., and that these provide FAR more security, and are FAR more important in this regard, than the choice of browsing engine.
Certainly McAfee and Symantec actually deal directly with many (if not most) of the vulnerabilities that emerge in IE (and Firefox, for that matter), whether they are caused by third party technologies or not.
Before I continue down this road I should point out that (a) I’m not answering why AOL is bothering to make a browser at all - that’s a different discussion for a different day - I’m answering why I think IE is a better choice than anything (currently) from the Mozilla Foundation as the underyling engine for that browser, and (b) this was a question that was asked even by our CEO, so I'm really not just rationalizing ex post facto :)
In my last post on this topic, I leveled a few scathing accusations against Firefox (vs. Internet Explorer), including:
- Firefox is safer/more secure
- Firefox is more standards compliant
- Firefox provides a better experience/is more powerful
- Firefox is cooler
So given all that, how is it possible that I think IE is a substantially better choice than Firefox (Mozilla/Gecko/etc. - I'm using Firefox as a proxy here) for our web browser, AOL Explorer?
Its always possible that we at AOL are just evil (and stupid :)). Or, perhaps its not so much THAT, as it is that we're part of a vast conspiracy to keep you down - that we are, in fact, "the man".
Let's parse this a little bit further to see where it leads us.
a) Firefox is safer/more secure
While it's true that there's been some noise over time about the number of security vulnerabilities in IE vs. Firefox, as well as the classification of those bugs, I think its just that: noise. I'll stipulate that, more likely than not - by any objective measure - Firefox has a safer browsing engine than IE.
There was, for example, a test comparing unpatched versions of each browser that demonstrated that Firefox is 21 times safer than IE (or to put that in less-alarmist language: unpatched IE had about a 1.52% greater rate of infection).
I'll posit, however, that Firefox (and its derivatives) are not safer in a meaningful way for consumers.
I say this for two primary reasons:
(1) Opportunity set.
Certainly the targeting opportunity is a factor (a key point: you'll note Firefox was NOT zero) - the idea being that Firefox users don't get targeted as much, because there are easier, broader pickings (*cough*IE *cough*AOL). How big a factor this is is difficult to say, but its hard to discount completely. And although I agree that the Firefox team has been (much more) diligent in patching the holes, new ones get found regularly.
I mention this because throwing our user base against this codebase would certainly create opportunity and incentive for the malicious. (Updated: for example this report)
(2) Third party technologies.
While Firefox may not support ActiveX (and much is made of this), it does support NATIVE plug-ins and extensions, including Flash, Java, Quicktime, Windows Media Player, etc. So it is subject to not only to its own (potential) problems, but to those of external vendors and technologies, much like Internet Explorer: Firefox just doesn't have as MANY (yet).
My main point on security, though, is slightly sideways: you're going to have MEANINGFULLY less infections and problems on your computer (viruses, spyware, etc.) only by having actual security software installed on the box: Antivirus, Antispyware, Firewall, et al., and that these provide FAR more security, and are FAR more important in this regard, than the choice of browsing engine.
Certainly McAfee and Symantec actually deal directly with many (if not most) of the vulnerabilities that emerge in IE (and Firefox, for that matter), whether they are caused by third party technologies or not.
Bear in mind, I'm not saying it SHOULD be so, but I am saying that it IS so, as a practical matter.
All in all, I think that scare tactics can be effective, but I'm not sure the delta is significant when you step back and look the entire scale of security problems, and, more importantly, effective remediations.
[Continued...]
March 6, 2006
Its an AIM world, you just live in it
It took a few months longer than anticipated (a few minor events took priority, at a corporate level), but we've finally begun to open up key AOL services, in very substantive ways.
Fundamentally, the newly announced (and extended) Open AIM SDK will enable developers to enhance the AIM network's reach and functionality.
What can you do with it:
- Extend AIM Triton at a low level
- Embed AIM functionality in your own applications
- Create your own version of the AIM client
- Embed presence functionality and communications touchpoints in web applications
To be clear: there are some restrictions and limitations on the ways in which you can leverage the AIM services we've made available, as we feel our way through the operational and business implications. But this should open up a broad set of possible applications on top of the AIM network and namespace immediately.
(In particular, Open AIM does NOT provide IM network interop with other Instant Messaging networks, at this time.)
We've got quite a road ahead of us in learning how to be "open". You'll be seeing a lot more over the next 6 months, both with desktop extensions and "bitless" web APIs (IM related and beyond) - but this is a pretty big first step for AOL.
Congratulations to the AIM team.
And for those who feel like this is too little, too late - I can only say: "Rome wasn't built in a day". Or the the related corollary: "Bite me - no one asked you."
(kidding! :P)
Momentum is building.
Fundamentally, the newly announced (and extended) Open AIM SDK will enable developers to enhance the AIM network's reach and functionality.
What can you do with it:
- Extend AIM Triton at a low level
- Embed AIM functionality in your own applications
- Create your own version of the AIM client
- Embed presence functionality and communications touchpoints in web applications
To be clear: there are some restrictions and limitations on the ways in which you can leverage the AIM services we've made available, as we feel our way through the operational and business implications. But this should open up a broad set of possible applications on top of the AIM network and namespace immediately.
(In particular, Open AIM does NOT provide IM network interop with other Instant Messaging networks, at this time.)
We've got quite a road ahead of us in learning how to be "open". You'll be seeing a lot more over the next 6 months, both with desktop extensions and "bitless" web APIs (IM related and beyond) - but this is a pretty big first step for AOL.
Congratulations to the AIM team.
And for those who feel like this is too little, too late - I can only say: "Rome wasn't built in a day". Or the the related corollary: "Bite me - no one asked you."
(kidding! :P)
Momentum is building.
March 3, 2006
How the West was screwy...
Updated: One of the commenters (anonymous - sorry, no attribution possible) posted this link: http://www.totallyabsurd.com/archive.htm. Funny, veeeery funny. Clearly NOT just a software issue - though I'm not sure I've seen the level of abuse outside the software business.
Is it me or does patent litigation seem COMPLETELY out of control? I mean, the absurdity of the "compliance" in some cases should maybe indicate to us that the inmates are running the asylum. Not that I have a particular sympathy for Microsoft, NTP, or even AOL (*ahem* us) in the broad sense on this - if you're indeed stomping on somebody's rights you should be stopped, big or small... but lately it seems like the letter of the law trampling over the spirit.
This doesn't seem to encourage innovation - it rewards speculative litigation and (what I view as) extortive licensing schemes. Somewhere along the way people arrived at this notion that just being smart, in and of itself, is a reason to get paid millions of dollars. Just because you're speculatively solving a problem that no one needed to solve YET doesn't (necessarily) make it novel or valuable - the patent process isn't supposed to be about being the mental Columbus; its supposed to reward INNOVATION, not discovery.
Ideas are EASY. Everybody's got an IDEA - for a book, a movie, a product, a company; sorry, BFD - "I have an idea..." seems like it is only SLIGHTLY higher on the value chain than "I really want this..." (and slightly below, "I know this guy..."). As Frank Herbert famously said (paraphrased), "Its writing that's the hard part". Perhaps I take umbrage because I believe in meritocracies and deriving value from ambushing successful companies, seem like, I dunno, not meritocratic...
Its not that I don't believe in intellectual property or its value in encouraging creativity, innovation, and value creation (quite the contrary) - it just that it seems like its become such an abstraction with this whole "software as process thing" that judging and valuing novel improvements in such a fast moving field has become very, very clouded.
Maybe its because software copyrights are all wrong? Copyrights seems to work much better in the music industry (overzealous RIAA tactics aside :P). They (in practice) protect the OUTPUT, that is, how the music sounds - not what instrument you used or how you played it. I think the obvious, but perhaps incorrect, extension to the software world was to copyright the CODE - just as you do the "music" (notes and arrangement), not the product (UI, algorithms, workflows, etc.). But perhaps that was a BIG mistake?... there isn't the same monotone relationship (no pun intended) between code and product as there is between notes and songs.
Or it could be as simple as some better way to judge the value of the patent with regard to the success and/or value of the infringing product/service... but the medical and insurance industries have been struggling with this for years, and it IS complicated.
Scrapping software patents completely seems extreme - I think we'd be back to secrecy and industrial espionage being the order of the day.
...I dunno - somehow it just feels like people are playing patent roulette at the expense of both the public (courts) and the private (shareholders) ... $100k on 13 black, please...
Is it me or does patent litigation seem COMPLETELY out of control? I mean, the absurdity of the "compliance" in some cases should maybe indicate to us that the inmates are running the asylum. Not that I have a particular sympathy for Microsoft, NTP, or even AOL (*ahem* us) in the broad sense on this - if you're indeed stomping on somebody's rights you should be stopped, big or small... but lately it seems like the letter of the law trampling over the spirit.
This doesn't seem to encourage innovation - it rewards speculative litigation and (what I view as) extortive licensing schemes. Somewhere along the way people arrived at this notion that just being smart, in and of itself, is a reason to get paid millions of dollars. Just because you're speculatively solving a problem that no one needed to solve YET doesn't (necessarily) make it novel or valuable - the patent process isn't supposed to be about being the mental Columbus; its supposed to reward INNOVATION, not discovery.
Ideas are EASY. Everybody's got an IDEA - for a book, a movie, a product, a company; sorry, BFD - "I have an idea..." seems like it is only SLIGHTLY higher on the value chain than "I really want this..." (and slightly below, "I know this guy..."). As Frank Herbert famously said (paraphrased), "Its writing that's the hard part". Perhaps I take umbrage because I believe in meritocracies and deriving value from ambushing successful companies, seem like, I dunno, not meritocratic...
Its not that I don't believe in intellectual property or its value in encouraging creativity, innovation, and value creation (quite the contrary) - it just that it seems like its become such an abstraction with this whole "software as process thing" that judging and valuing novel improvements in such a fast moving field has become very, very clouded.
Maybe its because software copyrights are all wrong? Copyrights seems to work much better in the music industry (overzealous RIAA tactics aside :P). They (in practice) protect the OUTPUT, that is, how the music sounds - not what instrument you used or how you played it. I think the obvious, but perhaps incorrect, extension to the software world was to copyright the CODE - just as you do the "music" (notes and arrangement), not the product (UI, algorithms, workflows, etc.). But perhaps that was a BIG mistake?... there isn't the same monotone relationship (no pun intended) between code and product as there is between notes and songs.
Or it could be as simple as some better way to judge the value of the patent with regard to the success and/or value of the infringing product/service... but the medical and insurance industries have been struggling with this for years, and it IS complicated.
Scrapping software patents completely seems extreme - I think we'd be back to secrecy and industrial espionage being the order of the day.
...I dunno - somehow it just feels like people are playing patent roulette at the expense of both the public (courts) and the private (shareholders) ... $100k on 13 black, please...
March 2, 2006
Influences and Beliefs
As a young kid: Bill Gates and Steve Jobs
As a young adult: John Warnock and Kai Krause
You probably know the first two :) And though they might be a bit obvious, what can I say? As a kid, they were gods to me.
I believe in meritocracies, the power of ideas, and the value of will. That's what these gentlemen, and their achievements, represent to me - that's what they taught me.
Looking at that now - as a slightly older adult - there's an interesting, consistent polarity (along an entreprenurial axis) between technology vision and creative vision, respectively, that has been attractive to me: Gates v. Jobs and Warnock v. Krause. And though I don't mean, in any way, to diminish the heroes of my youth - who have undeniably proven themselves as adept technocratic giants, agile business leaders and humanitarian luminaries - John Warnock is 10 times the technologist Bill Gates will ever be, and Kai Krause is 10 times the creative visionary Steve Jobs will ever be. What can I say? Success (and even leadership) is not the same as vision.
Don't believe me?
That's OK - my beliefs don't require that you do :)
I do find my value system evolving, though, as I've gotten (slightly) older, particularly now that I have kids.
As a young adult: John Warnock and Kai Krause
You probably know the first two :) And though they might be a bit obvious, what can I say? As a kid, they were gods to me.
I believe in meritocracies, the power of ideas, and the value of will. That's what these gentlemen, and their achievements, represent to me - that's what they taught me.
Looking at that now - as a slightly older adult - there's an interesting, consistent polarity (along an entreprenurial axis) between technology vision and creative vision, respectively, that has been attractive to me: Gates v. Jobs and Warnock v. Krause. And though I don't mean, in any way, to diminish the heroes of my youth - who have undeniably proven themselves as adept technocratic giants, agile business leaders and humanitarian luminaries - John Warnock is 10 times the technologist Bill Gates will ever be, and Kai Krause is 10 times the creative visionary Steve Jobs will ever be. What can I say? Success (and even leadership) is not the same as vision.
Don't believe me?
That's OK - my beliefs don't require that you do :)
I do find my value system evolving, though, as I've gotten (slightly) older, particularly now that I have kids.
March 1, 2006
JavaScript Applications, pt 2
Updated: Continued in pt 3, Optimization and Compilers
As my last post on this topic was remarkably content-free (by that I mean technically :)) for an article of its size, I thought I'd make this one a little denser. There's nothing I'll cover that's not in most every JavaScript tutorial of any sanity or advancement, but hopefully I can help make the "why?" a little clearer when all is said and done.
First, by way of some definitions, JavaScript is a strong, dynamically typed language. By that I mean that variables can be assigned, well, anything, and each "thing", during run-time, knows explicitly what type it is. We would say a compiled language like C is a weak, statically typed language because types are enforced at compile-time, and "things" don't implicitly know what type they are (e.g. you can forcibly change and/or override "types" in C).
JavaScript, like most dynamically typed languages, is generally an interpreted language. Resolution from instruction to machine code happens during program execution, usually through explicit (i.e. software decoded) instruction dispatching. I say "generally" because compilers like Flash (yes, the Flash authoring tool is a JavaScript compiler) and JScript.NET show that it doesn't HAVE to be an interpreted language. Still, there are limits to what a compiler can do because the dynamism implies that much of the object information is only available at run-time.
From a performance perspective, JavaScript (as in the browser) is 500 to 1000 times slower than compiled C code. To put that in context, imagine your 5 GHz Pentium IV ran at the same speed as your 4.77mhz original IBM PC. Yes, the one with 4 colors, and a 40x25 character display (ok, 80x25 in "high-res" mode). In practice, the delta is somewhat offset by the fact that the rich display engine, parser, and ancillary high-level functions connected to the interpreter run muuuuuch faster than anything your 4.77mhz 8086 PC could do.
The Microsoft JScript interpreter in IE and the Spider Monkey interpreter in Firefox run at about the same speed, roughly. Each are faster at some basic computing tasks, though I'd give the edge to IE hands down, performance-wise. Conversely, DOM access in Firefox seems faster, while layout and display in IE is usually better. So it all tends to wash out in the end - performance-wise. Incidentally, in some special cases, JScript.NET and the like (as in, like Flash 8.5) can do significantly better, but those paths have their own VERY hidden traps (which I'll explain some examples of in detail in a future post).
JavaScript has some nice attributes:
- Its truly dynamic: no compiler, easy to learn
- Error resistant: it generally just keeps working
- Ubiquitous runtime: the browser, et al
- Flexibility: simple rules, complex patterns, e.g. functions are objects
- Standardization: ECMA 262 - Javascript is often called "ECMAScript"
And on the downside:
- Its truly dynamic: no compiler - means no compile time errors
- Error resistant: it generally keeps working - which makes design holes hard to find
- Ubiquitous runtime: except its buggy as crap-all
- Flexibility: simple rules, complex patterns, e.g. functions are objects - what does that actually mean?
- Opaque costs: performance and memory (hah! - you thought I was going to say "Standardization" :P)
There's a lot of power afforded in the dynamism of the language. It allows for very flexible design patterns (remember we discussed that notion?), as with function callbacks for example, which are common in UI development.
In JavaScript, you can do things like:
(notice the DYNAMIC internal/nested function definitions)
Let's parse this in a bit more detail, because it captures much of the problem and opportunity in JavaScript.
First, you should understand that declaring a function is no different than declaring a variable, and has all of the associated scoping rules in effect. What this means is that "function myFunc(a) {...}" is really the same as "myFunc = function(a){...}" - its JUST a declaration of a function object and assignment to a global variable, in this case "myFunc".
A lot of the confusion arises from the abstraction of dynamic execution on top of (essentially) C-like syntax. Although functions in JS look like blocks of executable code (in the compiled-once, block-of-memory sense), they're really just dynamic objects. And when you declare a nested function, as we did above, the assignment of that function to the locally scoped variable "internalFunc" happens during each and every execution of the function. So why is this a problem?
Two factors make this an issue.
One, JavaScript is a dynamic language, as we said. Even properties on objects are strongly, dynamically bound. Translation? Each instance of each variable on each object creates a property pair hashtable entry on that object. The memory usage can grow quickly. It can easily be more than 64 bytes for property assignments, PER property, PER object instance, NOT counting the length of the property string itself.
Two, as noted in this basic tutorial on object-oriented JavaScript programming, here's how you might make a simple, custom JS object:
See the problem?
This code will essentially create locally scoped variables in the stack frame (the nested functions) and assign them to dynamic properties each time this "Circle" object is created. That is, although the inner functions are not PARSED each time you create a "Circle", new instances of the inner functions are assigned to new dynamic properties on the new object instance EACH time you construct the object, wasting both time and space.
JS has a built-in solution to this, called the "prototype" property, and I'll discuss how that works - and how its different and distinct from class derivation. Part of understanding the distinction, in the trivial case, comes from the (obvious) understanding of basic JS optimization, that:
...is a lot slower, at least in JavaScript, than:
...because after all, JS is a dynamic language. I'll provide some specific JavaScript performance tips and JavaScript benchmarks to make the points clearly.
More soon(-ish).
As my last post on this topic was remarkably content-free (by that I mean technically :)) for an article of its size, I thought I'd make this one a little denser. There's nothing I'll cover that's not in most every JavaScript tutorial of any sanity or advancement, but hopefully I can help make the "why?" a little clearer when all is said and done.
First, by way of some definitions, JavaScript is a strong, dynamically typed language. By that I mean that variables can be assigned, well, anything, and each "thing", during run-time, knows explicitly what type it is. We would say a compiled language like C is a weak, statically typed language because types are enforced at compile-time, and "things" don't implicitly know what type they are (e.g. you can forcibly change and/or override "types" in C).
JavaScript, like most dynamically typed languages, is generally an interpreted language. Resolution from instruction to machine code happens during program execution, usually through explicit (i.e. software decoded) instruction dispatching. I say "generally" because compilers like Flash (yes, the Flash authoring tool is a JavaScript compiler) and JScript.NET show that it doesn't HAVE to be an interpreted language. Still, there are limits to what a compiler can do because the dynamism implies that much of the object information is only available at run-time.
From a performance perspective, JavaScript (as in the browser) is 500 to 1000 times slower than compiled C code. To put that in context, imagine your 5 GHz Pentium IV ran at the same speed as your 4.77mhz original IBM PC. Yes, the one with 4 colors, and a 40x25 character display (ok, 80x25 in "high-res" mode). In practice, the delta is somewhat offset by the fact that the rich display engine, parser, and ancillary high-level functions connected to the interpreter run muuuuuch faster than anything your 4.77mhz 8086 PC could do.
The Microsoft JScript interpreter in IE and the Spider Monkey interpreter in Firefox run at about the same speed, roughly. Each are faster at some basic computing tasks, though I'd give the edge to IE hands down, performance-wise. Conversely, DOM access in Firefox seems faster, while layout and display in IE is usually better. So it all tends to wash out in the end - performance-wise. Incidentally, in some special cases, JScript.NET and the like (as in, like Flash 8.5) can do significantly better, but those paths have their own VERY hidden traps (which I'll explain some examples of in detail in a future post).
JavaScript has some nice attributes:
- Its truly dynamic: no compiler, easy to learn
- Error resistant: it generally just keeps working
- Ubiquitous runtime: the browser, et al
- Flexibility: simple rules, complex patterns, e.g. functions are objects
- Standardization: ECMA 262 - Javascript is often called "ECMAScript"
And on the downside:
- Its truly dynamic: no compiler - means no compile time errors
- Error resistant: it generally keeps working - which makes design holes hard to find
- Ubiquitous runtime: except its buggy as crap-all
- Flexibility: simple rules, complex patterns, e.g. functions are objects - what does that actually mean?
- Opaque costs: performance and memory (hah! - you thought I was going to say "Standardization" :P)
There's a lot of power afforded in the dynamism of the language. It allows for very flexible design patterns (remember we discussed that notion?), as with function callbacks for example, which are common in UI development.
In JavaScript, you can do things like:
(notice the DYNAMIC internal/nested function definitions)
function myFunc(a)
{
if (a==1) {
function internalFunc(b) {return a+b;}
}
else {
function internalFunc(b) {return a*b;}
}
return internalFunc(a+a);
}
v1 = myFunc(1); //v1 = 3
v2 = myFunc(2); //v2 = 8
Let's parse this in a bit more detail, because it captures much of the problem and opportunity in JavaScript.
First, you should understand that declaring a function is no different than declaring a variable, and has all of the associated scoping rules in effect. What this means is that "function myFunc(a) {...}" is really the same as "myFunc = function(a){...}" - its JUST a declaration of a function object and assignment to a global variable, in this case "myFunc".
A lot of the confusion arises from the abstraction of dynamic execution on top of (essentially) C-like syntax. Although functions in JS look like blocks of executable code (in the compiled-once, block-of-memory sense), they're really just dynamic objects. And when you declare a nested function, as we did above, the assignment of that function to the locally scoped variable "internalFunc" happens during each and every execution of the function. So why is this a problem?
Two factors make this an issue.
One, JavaScript is a dynamic language, as we said. Even properties on objects are strongly, dynamically bound. Translation? Each instance of each variable on each object creates a property pair hashtable entry on that object. The memory usage can grow quickly. It can easily be more than 64 bytes for property assignments, PER property, PER object instance, NOT counting the length of the property string itself.
Two, as noted in this basic tutorial on object-oriented JavaScript programming, here's how you might make a simple, custom JS object:
function Circle(radius) {
function getArea() { return (radius*radius*3.14); }
function getCircumference() { return (radius*2*3.14); }
this.radius = radius;
this.getArea = getArea;
this.getCircumference = getCircumference;
}var c = new Circle(5);
See the problem?
This code will essentially create locally scoped variables in the stack frame (the nested functions) and assign them to dynamic properties each time this "Circle" object is created. That is, although the inner functions are not PARSED each time you create a "Circle", new instances of the inner functions are assigned to new dynamic properties on the new object instance EACH time you construct the object, wasting both time and space.
JS has a built-in solution to this, called the "prototype" property, and I'll discuss how that works - and how its different and distinct from class derivation. Part of understanding the distinction, in the trivial case, comes from the (obvious) understanding of basic JS optimization, that:
for (i=0; i<100; i++) a.b.c.d(v);...is a lot slower, at least in JavaScript, than:
var f=a.b.c.d;
for (i=0; i<100; i++) f(v);...because after all, JS is a dynamic language. I'll provide some specific JavaScript performance tips and JavaScript benchmarks to make the points clearly.
More soon(-ish).
Subscribe to:
Posts (Atom)